
When it comes to AI-enabled automation, we need to shift our mindset from a binary state, where we have no automation or full automation, to a spectrum of automation.
Intelligent Document Processing AI
I borrowed Andrew NG’s AI spectrum and localized it for the Intelligent Document Processing (IDP) subdomain, focusing on automating field extraction on a document to study the spectrum. Field extraction refers to using a combination of AI and algorithms to perform OCR (Optical Character Recognition) and find values from a document. Our AI deployment options would be the following:
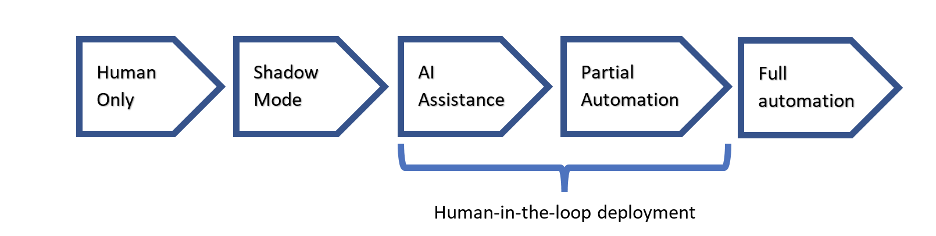
Human Only
This is where human validators, also known as indexers, enter the field’s value or perform a lookup to find the correct value from a list. No AI is involved with this deployment option.
Shadow Mode
In this mode, the humans are still indexing the data, choosing the correct format and manually performing the task, but the AI collects the data to help a machine learning team evaluate the AI’s performance before making the solution ready for the next level of automation.
AI Assistance
This is where the fields are extracted by the system and always presented to the indexer for verification or correction. Extraction of a field means that the value is prepopulated on a form and made editable for the indexer, the value’s location on the form is highlighted, and a snippet of the form with the field’s data is shown to the indexer.
Partial Automation
The AI extracts some fields, with high confidence and no mistakes. For the rest, where the AI is not confident, the system will present the extracted value to the indexer for validation.
Full Automation
The machine extracts all the fields correctly and without any mistakes.
A similar spectrum applies to classification and separation problems in the context of IDP.
Adding the Performance lens
Taking the level of performance into account, we can also break down the partial automation deployment option into two more sub-options:
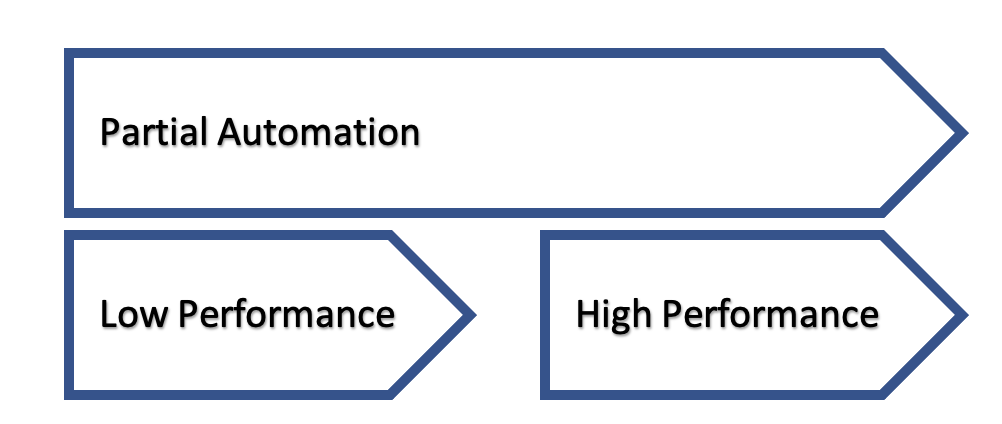
Low Performance
In the context of field extraction, this is the option of letting indexers verify most of the fields.
Training the system to automatically extract a low percentage of a field’s variations with high precision can usually be achieved relatively quickly. (for the sake of this example, let’s say 1-2 days of effort takes us to 50% partial automation) Since achieving low accuracy requires less effort, the productivity gain achieved by spending the time results in a reasonable return on the effort. In other words, this option has a higher ROI or return on investment.
High Performance
In the case of high-performance partial automation for extraction, most of the values extracted for a field are already confident and accurate and are not shown to the user. The same idea applies to classification and separation as well. Building an AI to achieve high-performance results, where a large percentage of .e.g, fields are automatically extracted with very high precision, comes with increasingly more difficulty and challenge. Using the previous example, getting to bump the performance from 50% to 80% might take an additional 6-7 days for that field. So, the 30% gain in performance comes with a diminishing return on our investment.
Road Ahead
As AI’s exponential progress continues, I expect the higher performance results to become achievable and attainable with less effort in the near future. For the time being, we should be diligent in our solutions to provide the maximum value and highest ROI for our clients versus the highest performing result.
Implication and Conclusion
Depending on the use case’s complexity, it would be prudent to break a complicated problem into multiple features (development phases and estimates) where e.g. we deliver an AI assistive solution before developing a partial automation AI. Or we provide a solution with partial automation and low performance, and then we can follow up with a high-performance phase later on. The most important consideration is to choose a point in the spectrum that helps us maximize the ROI and create the most value for our customers.