
This article goes over fuzzy lookup, how it works conceptually, a shocking revelation for your end-users and how to deal with it.
Introduction
A solid strategy to increase user’s productivity is to deploy your extraction as partial automation with the help of fuzzy lookups.
What is fuzzy lookup
“Fuzzy search is a technique of finding strings that closely (but not exactly) match a pattern in a fuzzy database.”
Let’s see an example to understand the technique better. Let’s consider the case of a typical drug receipt that you receive for a prescription drug from the pharmacy. Let’s also assume that we are looking to extract the pharmacy phone number from the receipt.

Your average capture developer would default to writing a regular expression and use the phone number pattern (XXX-XXX-XXXX) to extract this field. A typical regular expression would be something like the expression below:
^(\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]\d{3}[\s.-]\d{4}$The issue with a regular expression approach is that the OCR results of the drug receipt might have errors, and your regular expression might not return any result (True Negative), or it might return an incorrect value confidently (False Positive). Both of these cases would lead to data quality errors, and your end-users would lose their trust in the system.
Even if you use some of the extraction services that utilize cutting-edge deep learning neural nets with great sizes and features, such as AWS Textract or Microsoft Form Recognizer, you still have to find a way to deal with false positives. Otherwise, your extraction would need to be deployed as AI Assistance.
When you use fuzzy lookups essentially, you will use all the data available on your document relevant to the pharmacy and use them all to find that particular one among all the pharmacies in, say, Canada.
The main difference between fuzzy lookup and other methods such as regular expression is that your system uses learning vs deterministic approaches. For example, my client receives up-to-date pharmacy records every week, and my system automatically learns about the new pharmacies and uses them for fuzzy lookup. Fuzzy lookup is also forgiving about OCR errors, and since it uses partial matching, you can still find the correct value even if the OCRed text was incorrect.
Levenshtein distance
Now let’s understand how fuzzy lookup works on a concept level. Fuzzy lookups use Levenshtein Distance between two strings to calculate how much two strings match. “Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other.”
For example, the Levenshtein distance between “rock” and “pocket” is 3, since the following three edits change one into the other, and there is no way to do it with fewer than three edits:
- rock → pock (substitution of “p” for “r”)
- pock → pocke (insertion of “e” at the end)
- pocke → pocket (insertion of “t” at the end).
In the case of fuzzy lookup, the Levenshtein distance is used in the following formula to calculate a fuzzy score percentage that represents how much two strings match:
int levDis = Lev_distance(Q, Mi)
int biggerString = max(strlen(Q), strlen(Mi))
double totalScore = (biggerString - levDis) / biggerStringFor example, the fuzzy score percentage of rock and pocket is 50%.
levDis = 3
biggerString = 6
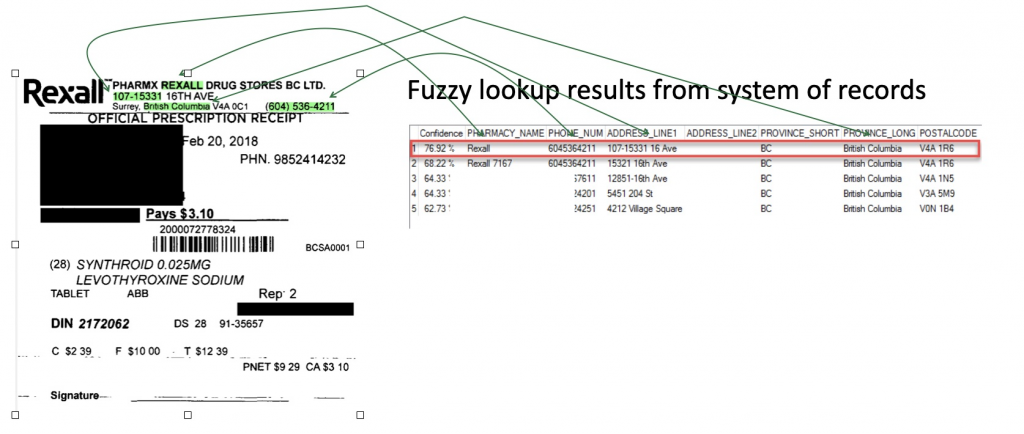
totalScore = (6-3)/6 = .5Now let’s go back to our pharmacy phone number example and check out the final score of the best pharmacy match in the image below. The best match was a Rexall pharmacy in BC with 79.92%.

This score is the average of fuzzy score of pharmacy name + fuzzy score of phone number + all the other fields that we have configured for the lookup:
TotalFuzzyScore = Average ( FuzzyScore(Fields1) + FuzzyScore (Fields2) + ...)In KTM, if you change the importance of a particular field, a weighted average is used instead of a simple average.
If you want to learn how fuzzy lookup is implemented, it uses the bag of words and the Vector Space Model. Wolfgang Radl has a great article on this worth reading.
Four cases of fuzzy matching
When you start using fuzzy lookup in your project, inevitably, you would come across the following four cases:
Case 1
This is the most straightforward case where the value that you are looking for is on the document. e.g. in the receipt below, the phone number on the receipt is accurate, and it matches what the fuzzy lookup has returned 100%.

Case 2
The value you are looking for is partially on the document or unreadable both by humans and machines. In the example below, the fourth digit is not readable.

Case 3
In this case, the value is not on the document but can be found in the system of records from which we are performing the fuzzy lookup.

Case 4
This is the case where the value is on the document but different than the system of records. In my experience, the system of record contains the accurate number since it has up-to-date records. e.g. in this case, the pharmacy had changed its phone number, but the drug receipt had been printed before the phone number change.


Index what you see
When I presented the 4 cases to my client, they told me they do not want the system to automatically find the values for case 2, case 3 and case 4. They were operating with the idea of “index what you see,” and they decided to remain with this principle when the project goes live. The main reason behind this decision was that if the system did not automatically find a match using fuzzy lookup, a manual fuzzy lookup would need to be performed by the human indexer. There is no problem searching all the Canadian pharmacies, but we also used the fuzzy lookup technique to find the patient name, patient address, etc. My client, strangely so, had reservations in providing a manual lookup that enabled the human indexers to search all the existing and new customers and find personal information such as a home address, phone number, etc.
So we had to build a logic that would essentially apply the concept of “index what you see.” This meant that we could only make a field bypass the review of human indexers if the particular subfield of interest, the pharmacy phone number, e.g., had a fuzzy score of 100%. Now I want to re-emphasize that the overall score of the pharmacy can still be 79%, while the fuzzy score of phone number is 100%.